第21届国际蛋白质组学大会于2022年12月4日到8日在墨西哥坎昆胜利召开,这是新冠疫情三年来人类蛋白质组组织(以下简称HUPO)首次线下会议,也是史上首次在拉丁美洲召开的HUPO大会。尽管受到疫情影响,本次大会仍然汇聚了全球36个国家和地区蛋白质组学领域的近千名专家学者。大会共安排了45场特邀报告,74场专题报告,500多份海报。
贺福初院士率领中国代表团出席会议,在大会期间展开了“人体蛋白质组导航计划”(以下简称“π-HuB计划”)旋风式的系列宣传、推介和组织活动,获得广泛而热烈的反响。此次蛋白组学领域科学家的线下会晤,一扫新冠疫情爆发以来的沉闷气氛,为重启全球科技交流与合作,推进海内外科技成果转化,复苏各地区组学产业活力注入了强心剂。
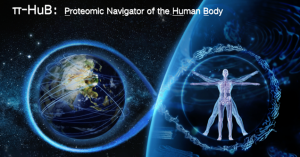
在第一天开幕式上,贺福初院士因其多年的对国际蛋白质组事业的贡献,就获得了2020年蛋白质组学杰出成就奖。除此之外,贺院士还给出了π-HuB:Proteomic Navigator of the Human Body 也就是人类大科学计划的启动报告(π-HuB),来邀请各国科学家到-人体蛋白质组导航计划中。


这项计划之前的基础工作有human proteome project, 也就是HPP 计划,在2020年完成涵盖了超过 90%的人类蛋白质。此外,《自然》杂志在 2014 年发表了两篇开创性论文,通过应用基于质谱的方法对数十种正常组织/器官进行分析,揭示了人类蛋白质组的初始版本。
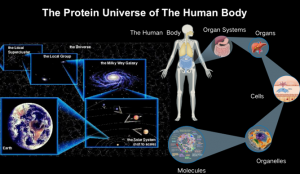
尽管取得了这些进步,但我们才刚刚开始触及表面,在更好地了解人类蛋白质组方面仍然存在挑战。这实际上是一个双重挑战。在人类方面,分子多样化在塑造体内万亿个细胞的人类蛋白质组中尤为明显。在人类生命方面,个体蛋白质组在一生中具有高度动态性,可以通过微生物组、营养物类型和环境状态等多种因素进行不同的重塑,这些都与人类健康和福祉有关。而这项计划旨在从各个角度,包含空间、时间、解读人体蛋白质宇宙。
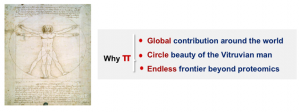
π-HuB之所以使用字母π,因π是圆的周长与直径的比值,所以它把圆定义为世界。而且,有趣的是,达芬奇著名的人体画作也被一个神秘的循环所包围。此外,π是无理数,它的数字不会结束或重复,因此它代表了人类蛋白质组无限动力学的无限边界,也象征着无国界的合作和对人体的奥秘无限探索。
更具体地,π-HuB计划细分成了四大目标:

1 绘制“空间蛋白质组图”
将人体分解成数字层次结构,从组织/器官到单细胞、蛋白质复合物,甚至是不同蛋白质形式的单个分子及其相互作用。随着单细胞蛋白质组学和空间蛋白质组学的不断发展,来自不同种族和性别的高分辨率蛋白质组学图谱可以联合各国科学家产生。
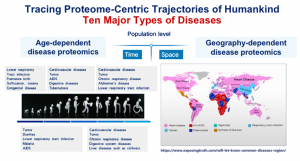
2 定义蛋白质组的时间和空间的概念,追踪以蛋白质组为中心的谱系轨迹
例如,我们可以收集人口蛋白质组学数据并追踪健康生命阶段(如繁殖、发育、成熟和衰老)中以蛋白质组为中心的谱系轨迹。我们应该考虑这些生命阶段以及许多其他因素,如性别、种族等,适当设计一些纵向队列来回答这个问题。
3 模拟元智人,通过计算建模建立一个元智人虚拟空间
此外,我们可以研究特定人群的蛋白质组如何适应营养、环境和共生,以及这些因素是否可以重塑蛋白质组,尽管我们知道所有这些因素都会对人类健康产生深远影响。例如,我们需要培养大量按主要饮食模式分类的健康个体,如东方饮食、日本饮食、西方饮食和地中海饮食;或主要根据地球温度或共生微生物组的类型按生态系统分类。所有这些数据及其潜在的生物信息最终可能会帮助我们将生活空间从地球扩展到未来的其他行星,如火星甚至太空更深处。
4 作为“参考空间”中导航,引导人体远离疾病/亚健康,保持健康状态
这个项目最重要的主题就是研究癌症、神经退行性疾病等重大疾病在进展和发展过程中的蛋白质组学变化。需要强调的是,π-HuB 将在人口水平上研究疾病蛋白质组,重点关注它们对寿命和生活区域的依赖性。因此,我们肯定需要国际合作来开发临床队列,用于从体液、FFPE 样本或穿刺活检中收集疾病蛋白质组。
此类分析将产生大量蛋白质组数据,因此我们需要一个计算框架来处理、分析和解释这些数据。因此,我们需要利用数据科学的方法创新,将蛋白质组数据与生物医学研究领域其他大型科学项目产生的数据相结合。因此,也可以结合π-HuB 第三个模拟一个元智人的目标,它可以是一个虚拟的状态空间,由分子水平上虚拟增强的生理表型和数字现实的融合创建,例如关于细胞、体液或穿刺活检的时空蛋白质组学信息。
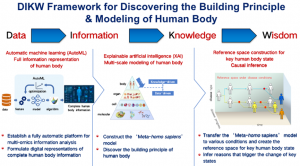
我们可以利用自动机器学习框架来开发多组学信息处理平台。然后,我们想利用基于深度学习的多尺度建模技术来学习一个名为“元智人”的人体动态模型,并通过可解释的人工智能解释学习到的模型,从而发现人体的构造原理 算法。最后,通过将“元智人”模型迁移到各种条件下,我们将能够为关键的人体状态创建参考空间,并通过因果推理推断出触发它们之间变化的核心因素。
有了 Meta-homo sapiens 模型或所谓的“导航器”,我们最终可能有机会在虚拟空间中进行路线规划,以进行早期疾病检测和拦截。
为了实现所有这些目标,我们需要在科学战略、可交付成果、下一代蛋白质组技术的开发和验证等方面仔细定义和完善该项目的路线图。这将通过整合全球多学科科学家社区的成果来进行全球合作和讨论。
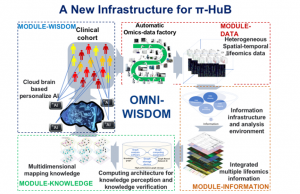
另一方面,拥有强大的动力来处理为该项目收集的大量样本并生成此类大数据显然至关重要。对此,中国团队正在尝试为π-HuB项目设计一个新的基础设施,取名为Omni-wisdom。它应该有一个所谓的“数据工厂”,用于高通量生产以蛋白质组学为中心的多组学数据。然后,可以使用最先进的计算方法处理数据,例如高性能计算系统、自动机器学习、可解释的人工智能、知识图等。所有这些方法最终将统一起来,为自动发现新生物学和临床实践新方法提供信息管道。

在过去的一年里,我们已经在广州建立了一个蛋白质组学数据工厂的试点,它可以作为 π-HuB 数据生成中心之一。现在它已经配备了17台尖端的LC-MS仪器,更重要的是它有不知疲倦的样品制备的自动化设备。
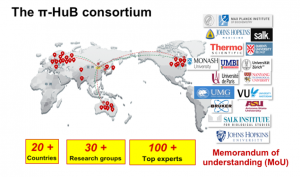
迄今为止,π-HuB 项目已经获得了 100 多位顶尖专家的支持,其中包括来自 20 个不同国家的多位诺贝尔奖获得者,并且这个名单还在不断增加。此外,数十个机构、大学签署了谅解备忘录,表明他们愿意加入这一伟大的努力。π-HuB 项目将在未来三十年的生物医学研究中发挥核心和催化作用,旨在为人类的健康和福祉提供分子水平的最终解决方案。

在π-HuB举行的启动仪式上,各国学者对π-HuB项目都表示了恭贺和支持,郭天南教授也主持了其中的问答环节,对蛋白质组学重量级学者的疑问组织讨论和解答。不确定的挑战需要一代又一代人的努力,来实现这三十年的宏伟计划。



作者 / 张芳菲